Mongo Sharding + GridFS
By Josh Fermin
What is Sharding?
Storing data across multiple nodes/machines.
A single machine may run out of storage or have bottlenecked reads and writes
Sharding is horizontally scalable - Add machines as demand increases.
Database Issues
High throughput and large amounts data put a lot of stress on a single server.
Set sizes larger than RAM stress I/O capacity
High query rates can exhuast CPU capacity of a single server.
Two Solutions
- Vertical Scaling:
- Add more CPU and storage resources to a single server
- Limitations: Expensive.
- Sharding (Horizontal Scaling):
- Distribute data set over multiple servers or shards
- Each shard is an independent db and all together they make up a single logical db.
Sharded Collection
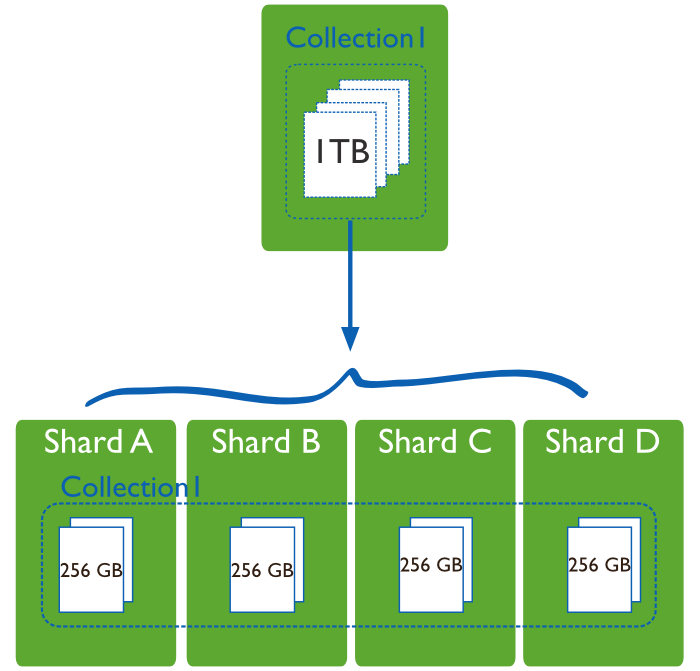
Sharding in MongoDB

Data Partitioning
Sharding happens on a collection level.
Sharding divides a collection's data by a shard key
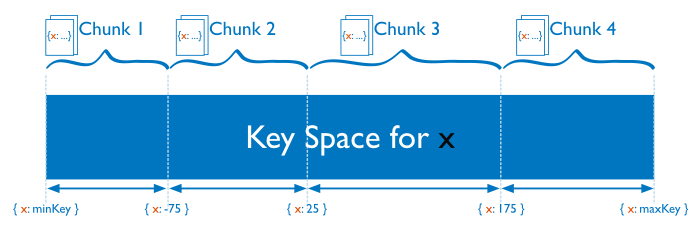
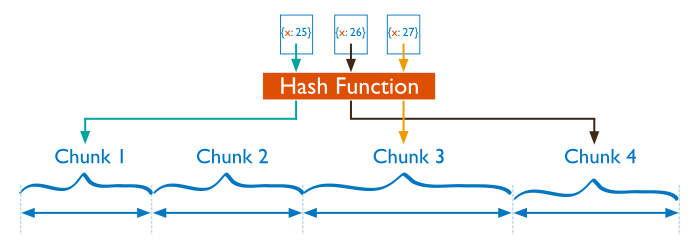
Two types of partitioning: range based and hash based
Ranged Based Paritioning
Hash Based Paritioning
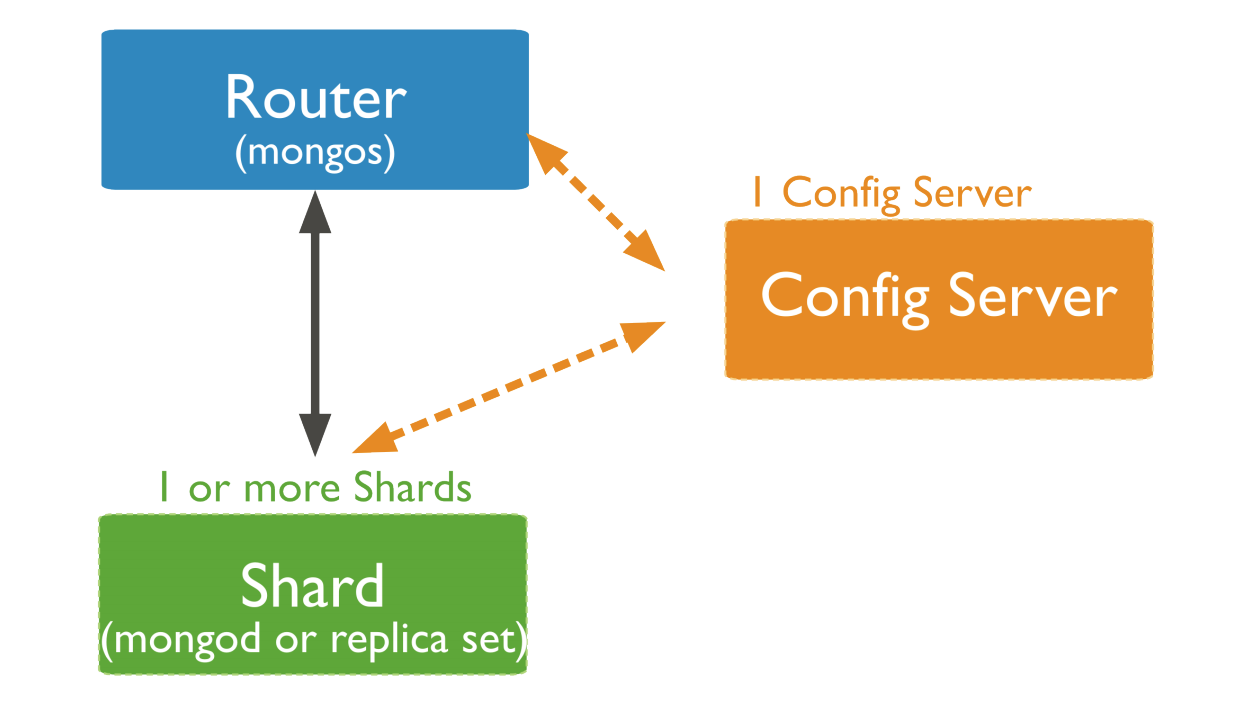
Mongo Sharding Tutorial
Taken from Mongo Docs.
Fire Up Config Server
Download Mongo heremkdir /data/configdbmongod --configsvr --dbpath /data/configdb- data/configdb is where server metadata will be stored
- In production, run configsvr on three different hosts
Setup Mongos - Routing Service
mongos --configdb localhost:27019 --port 27017- Lightweight, do not require data directories
- Usually have two of these in production
Create DBs for Shards
mkdir /data/shard1mongod --dbpath /data/shard1 --port 27018 --shardsvr- This starts a standalone mongod instance
Create another Shard
mkdir /data/shard2mongod --dbpath /data/shard2 --port 27020 --shardsvr- Data will be partitioned to these two shards, based on shard key
Fire up mongos shell
mongo --port 27017mongos> sh.addShard("localhost:27018"){ "shardAdded": "shard0001", "ok" : 1 }
mongos> sh.addShard("localhost:27020"){ "shardAdded": "shard0002", "ok" : 1 }
Sharding on DB/Collection Level
First create a database and a collection:
mongos> use testDBmongos> db.createCollection(testCollection)
Then enable sharding on each:
Second param is choosing the shard key as md5 with hash partitioning. For range based do: "md5":1mongos> sh.enableSharding(“testDB”)mongos> sh.shardCollection(“testDB.testCollection”, { “md5”:”hashed” })
What we just did
So What is this GridFS business?
GridFS is an extension on top of mongo
Allows you to store/retrieve files that exceed BSON doc limit of 16mb
How is that possible?
Instead of one doc per file, GridFS breaks it into 255k chunks.
Each chunk becomes a separate document.
When you query for a file, the driver or client will reassemble it as needed.
GridFS Collections
GridFS uses two collections to store files.
- Chunks: store binary chunks
- Files: store file metadata
Implementation
Two ways:
- Drivers: Basically a high level API
- mongofiles: mongo shell command line tool
Example - C# Driver
using MongoDB.Driver;
using MongoDB.Driver.GridFS;Connect to mongos and get info
MongoClient client = new MongoClient("mongodb://localhost:27017");
MongoServer server = client.GetServer();
MongoDatabase database = server.GetDatabase("testDB");
MongoCollection testCollection = database.GetCollection("testCollection");GridFS Driver
MongoGridFS gfs = new MongoGridFS(database);
gfs.Upload(@"C:\test.txt");Conclusion
- If everything was set up correctly you can now read/write any files you want (movies, music, etc) into mongo using GridFS
- You can shard on the chunks collection if you'd like giving you horizontal scaling.
- Learned how to use MongoDB Sharding and GridFS API